我们需要机器学习的可解释性,原因是就算现在机器能够做出正确的答案,也不代表它非常聪明。现在银行用机器学习的模型来辨别是否贷款给一个用户,但政策规定必须给出一个理由,这是我们需要机器学习的模型是具有解释力的。有些重要的事情,机器学习不给出一个理由,我们很难相信是正确的判断。
当机器学习具有解释力的时候,我们可以凭借解释的结果来修正我们的模型。
Explanation分为两种。一种是Local-Explanation,一种是Global-Explanation。前者是根据某一个数据回答问题(为什么这是猫),后面是没有给具体数据,先给一个分类一个定义(什么图片叫做猫)。
Local-Explanation

如果你想要知道图片中每个区域的重要性的时候,一个方法是把每部分分别拿掉。再看分类正确的几率。
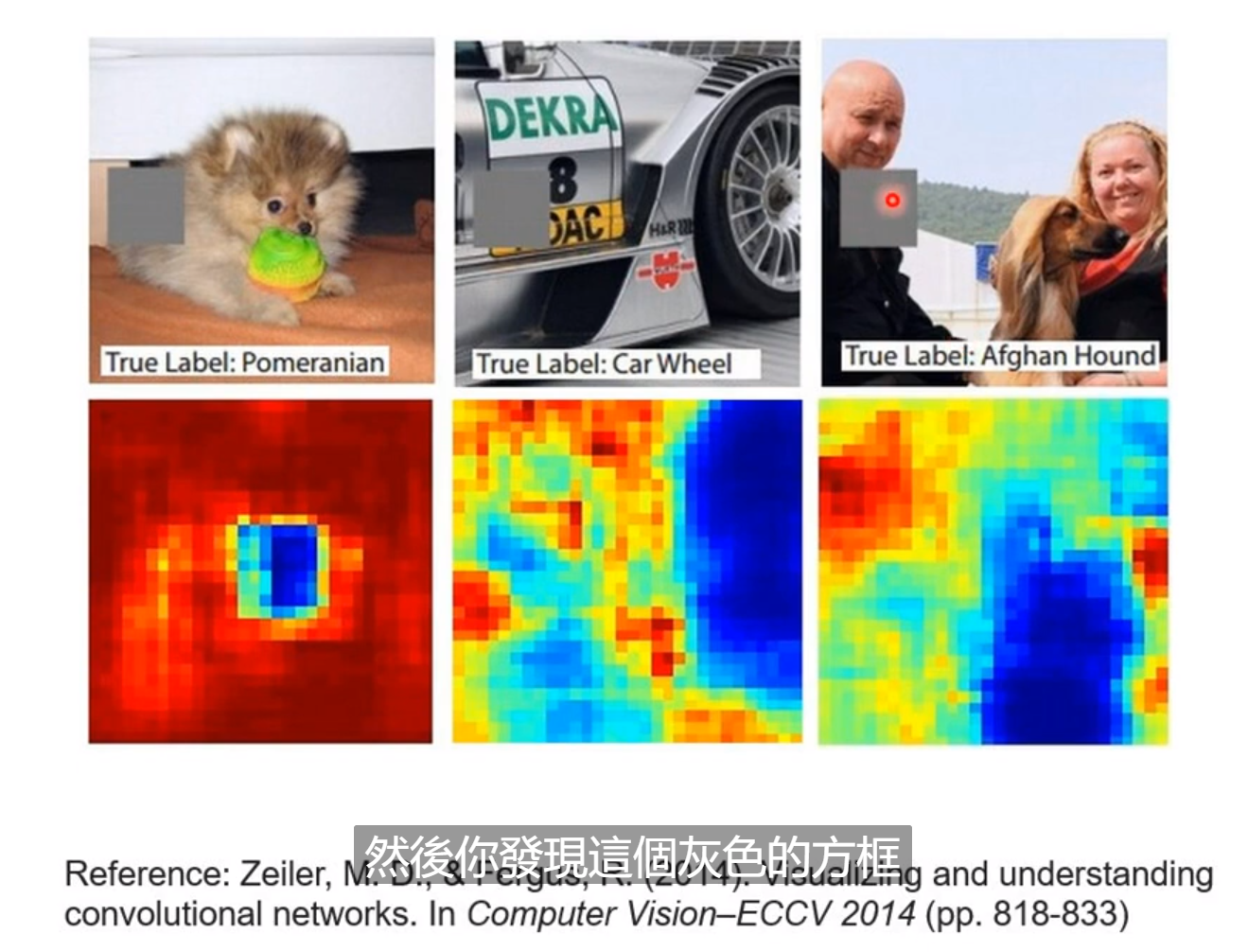
图中蓝色的区域表明拿掉之后识别的准确率大大降低,说明了其重要性,可解释性大大提高。
还有一个比较直接的方法是直接测试每一个pixels(像素)的梯度,把某一个pixel的值直接作一个小小的变化,观察输出结果跟正确答案的差距的变化,变化程度越大,重要性越高。
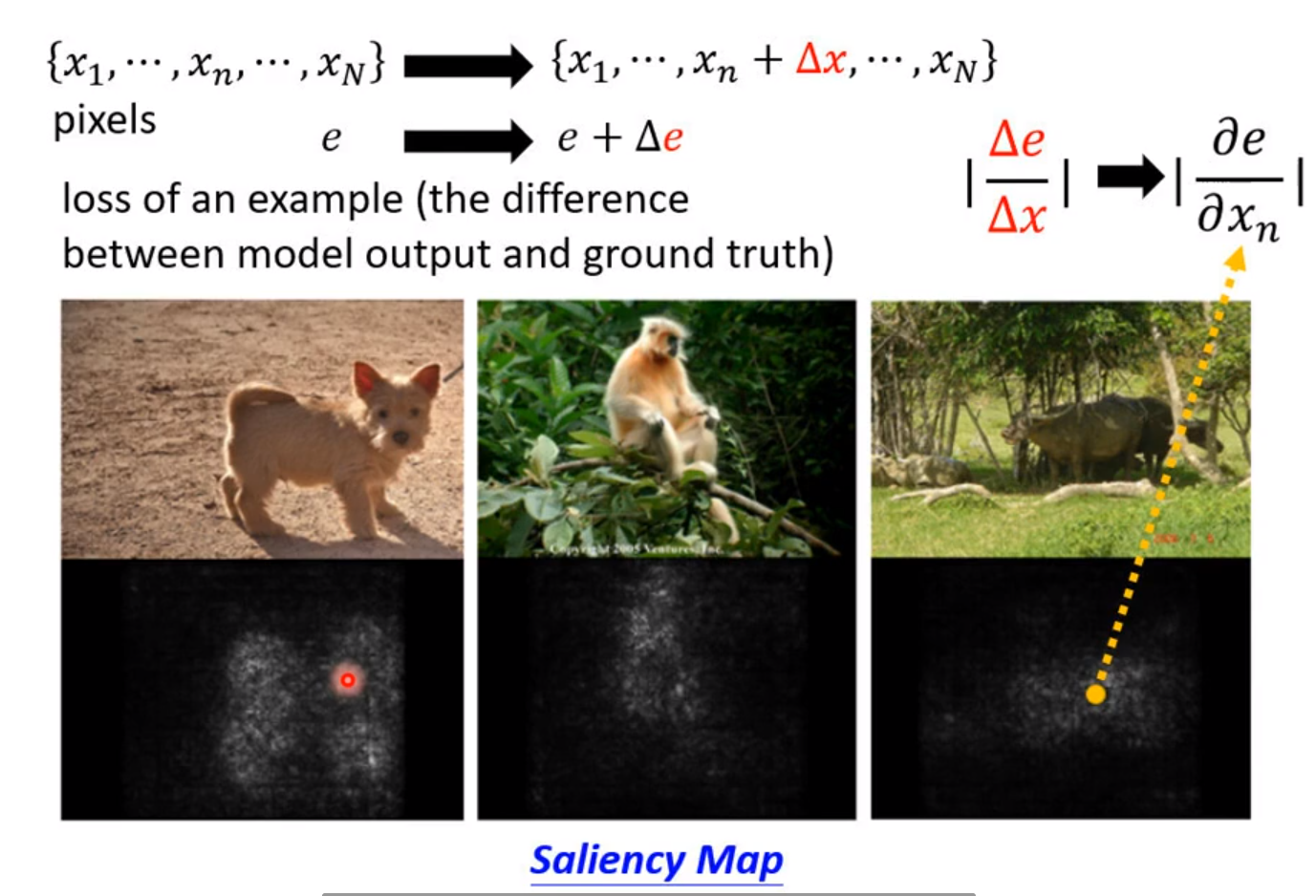
这就是Saliency-Map。
有时我们画的图亮点可能会比较分散,让人疑惑,这里有可以把图画得更好的方式。SmoothGrad是一种。方法是在图片上加上各种各样不同的噪声。每张图片都计算Saliency-Map。平均起来就可以得到比较明显的结果。

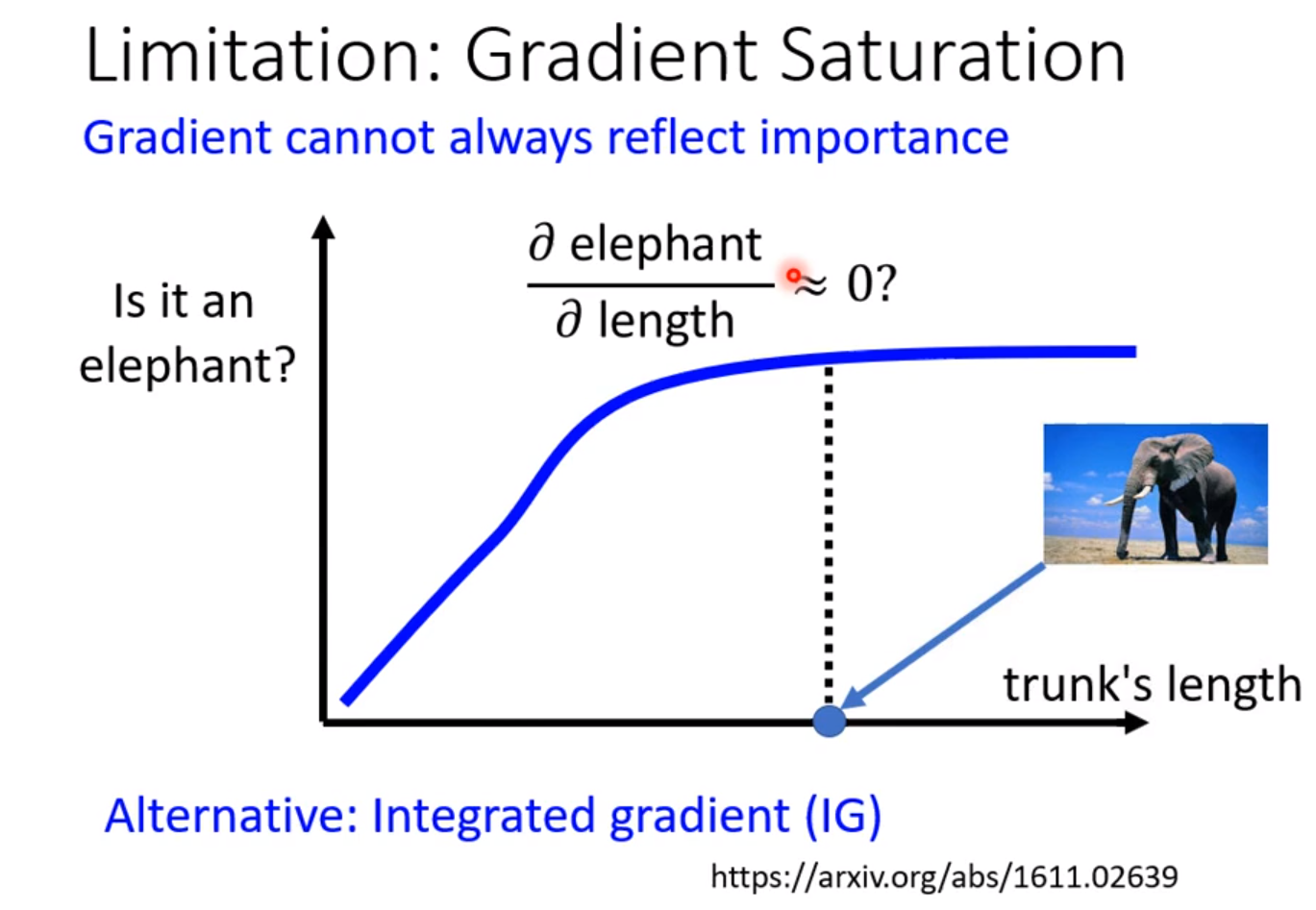
有的时候光看梯度是无法察觉一件事物的重要程度的。论文链接如下图:
有时我们可以把一个高维的向量降导二维,然后放到图中观察,这样就可以用肉眼观察的方式看出区别。

这里有一个Probing的方法,就是用探针插入network看看发生什么事。我们可以去训练一个分类器,插入中间层查看Embedding之后的结果是否包含我们需要的信息,如果分类器怎么的得不到好结果,可能中间层已经不包含我们需要的信息。但要注意也有可能是model没有train好的缘故。
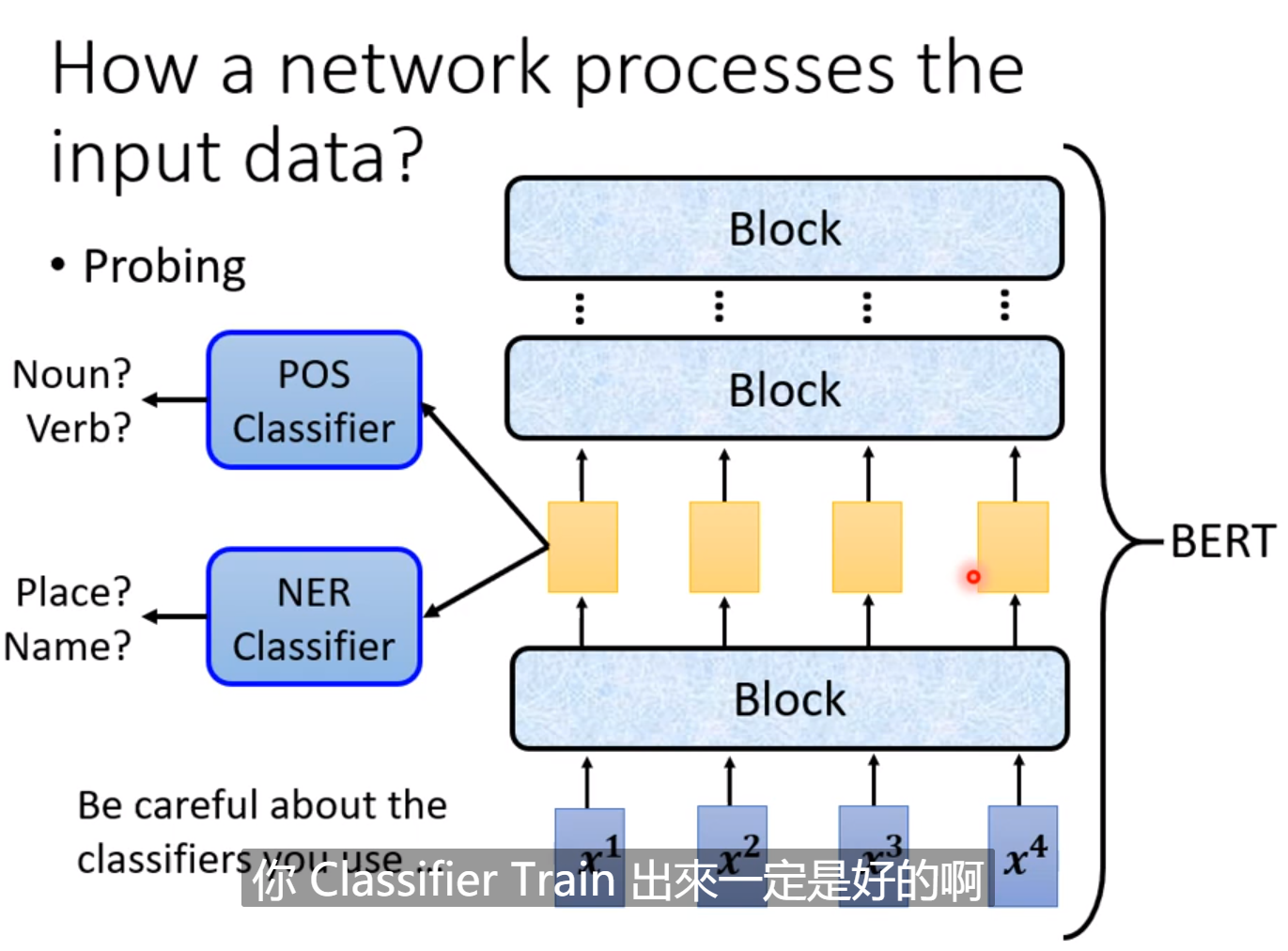
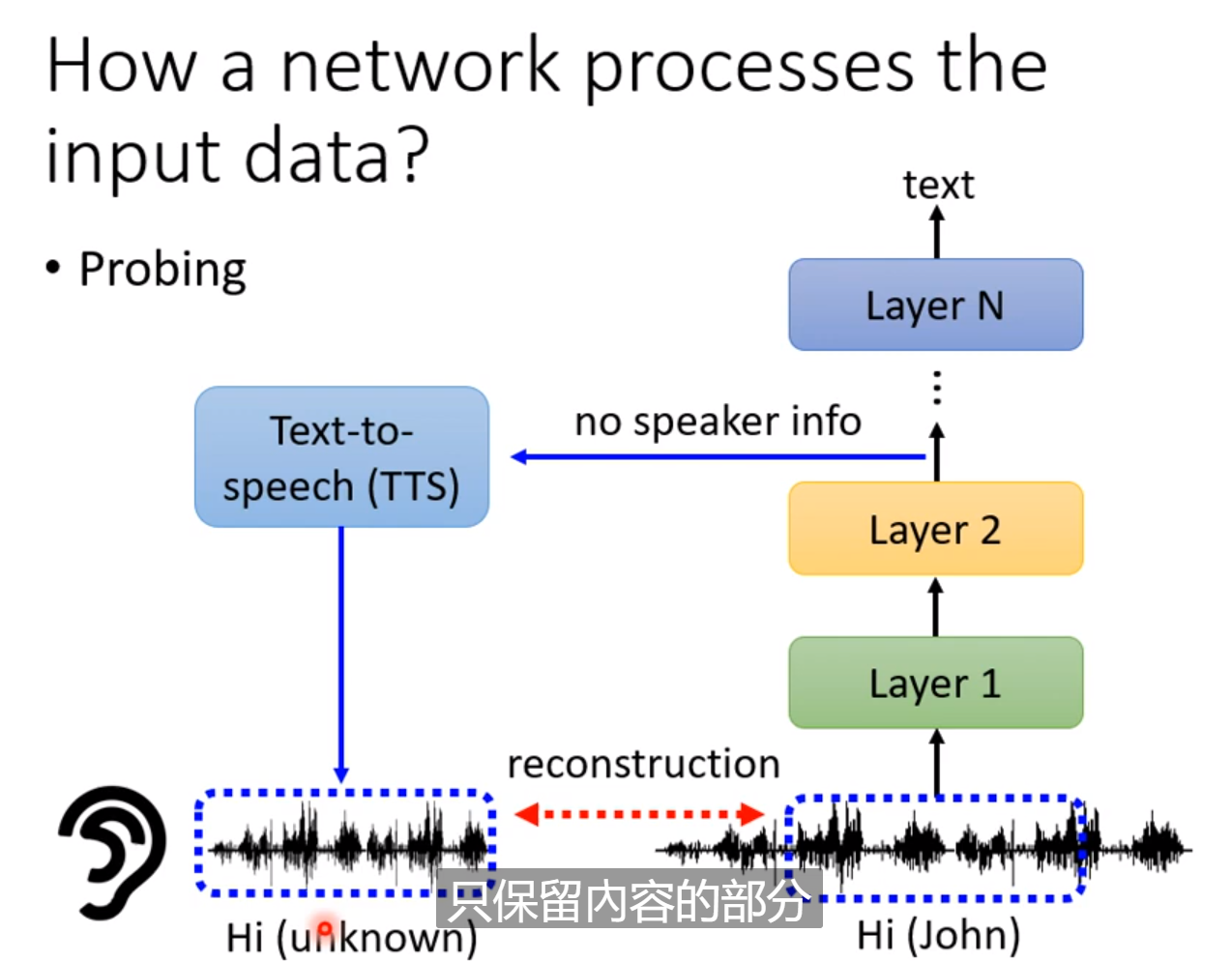
通过probbing的复现,我们可以发现每一层的神经网络的作用(例如过滤噪音)的影响有多大。
Global-Explanation
Global-Explanation并不是根据某一个数据给出解释,而是把训练好的模型拿出来,检查其中的参数,得出对一个分类的定义。
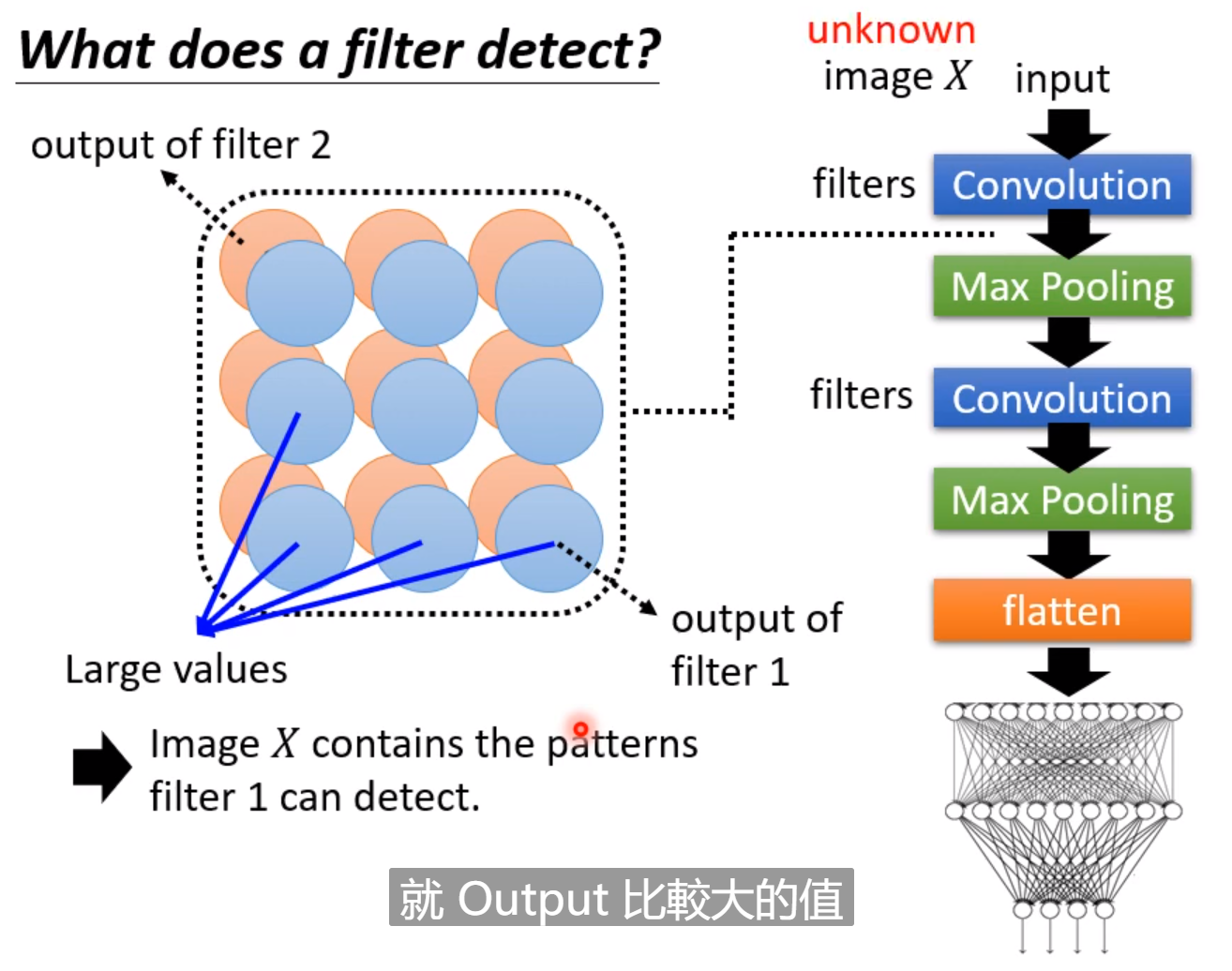
例如上图,卷积层的输出有很多的filters。如果某一层的filter中的一些位置有比较大的值,说明这个部位负责侦测某些特征。如果fillter1看到了这些pattern,那么就在feature-map看到比较大的值。如果我们要比较直观看到这种模式,我们需要创造一张图片,这张图片包含Filter1需要Detect的Pattern。
因此我们需要找一张图片,使得其中输出每一个点的总和越大越好。
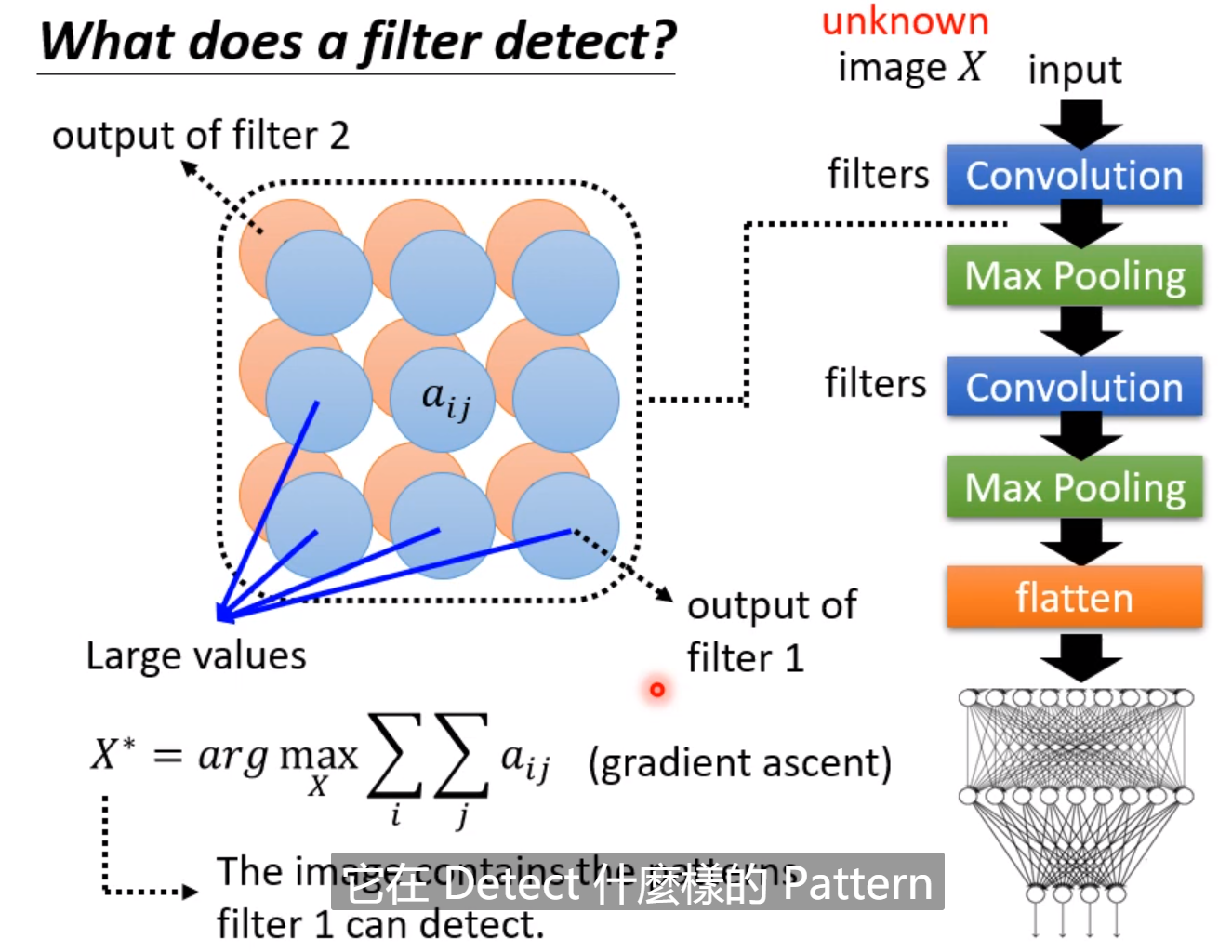
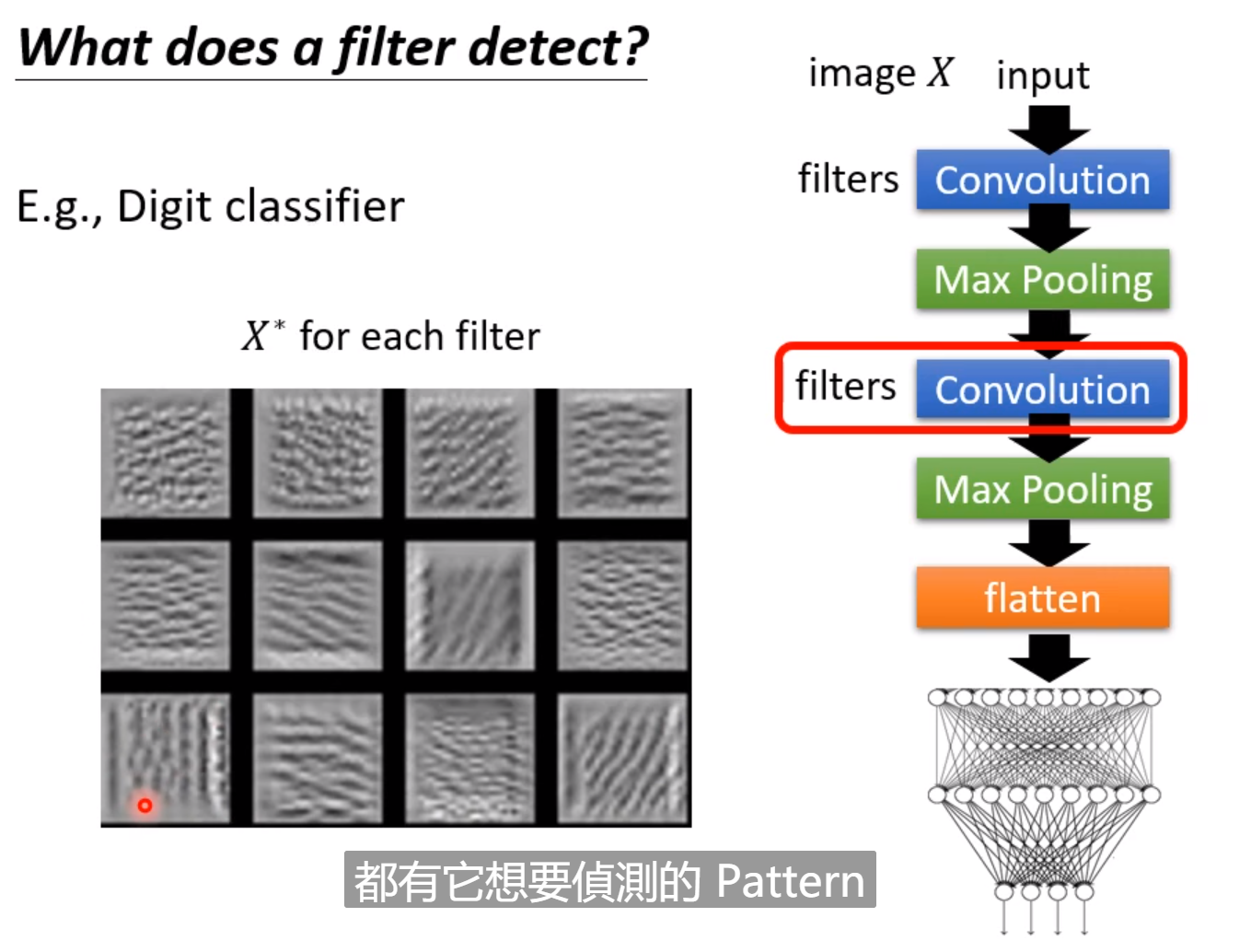
把每一个filter对应的图片画出来,就能看出每个filter所要侦测的pattern。可以看出有的filter的任务是侦测竖线,有的是侦测横线。
然而你想要找一个某分类最高分的图片来查看识别的pattern,往往看到的是一堆杂讯,而且很多杂讯的信心分数非常高,这部分涉及Adversarial-Attack,有时候微小的噪声变化都能使输出产生翻天覆地的变化。
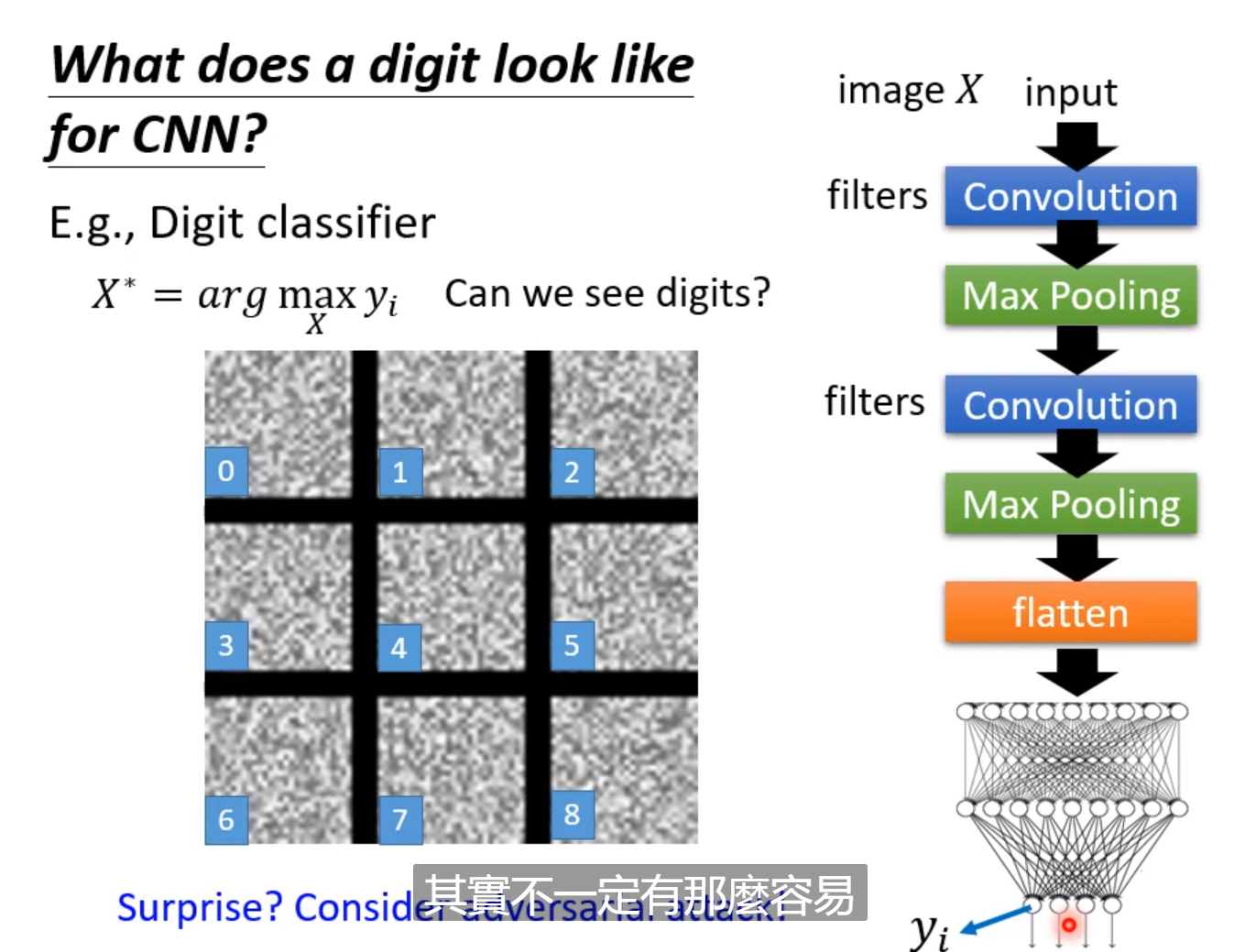
这时候我们需要人为加入限制,让这种pattern符合人的习惯,我们可以让白色像素点越少越好。

往往我们要得到更加令人满意的结果,我们就需要更加自己对一件事物的了解下非常多的限制。
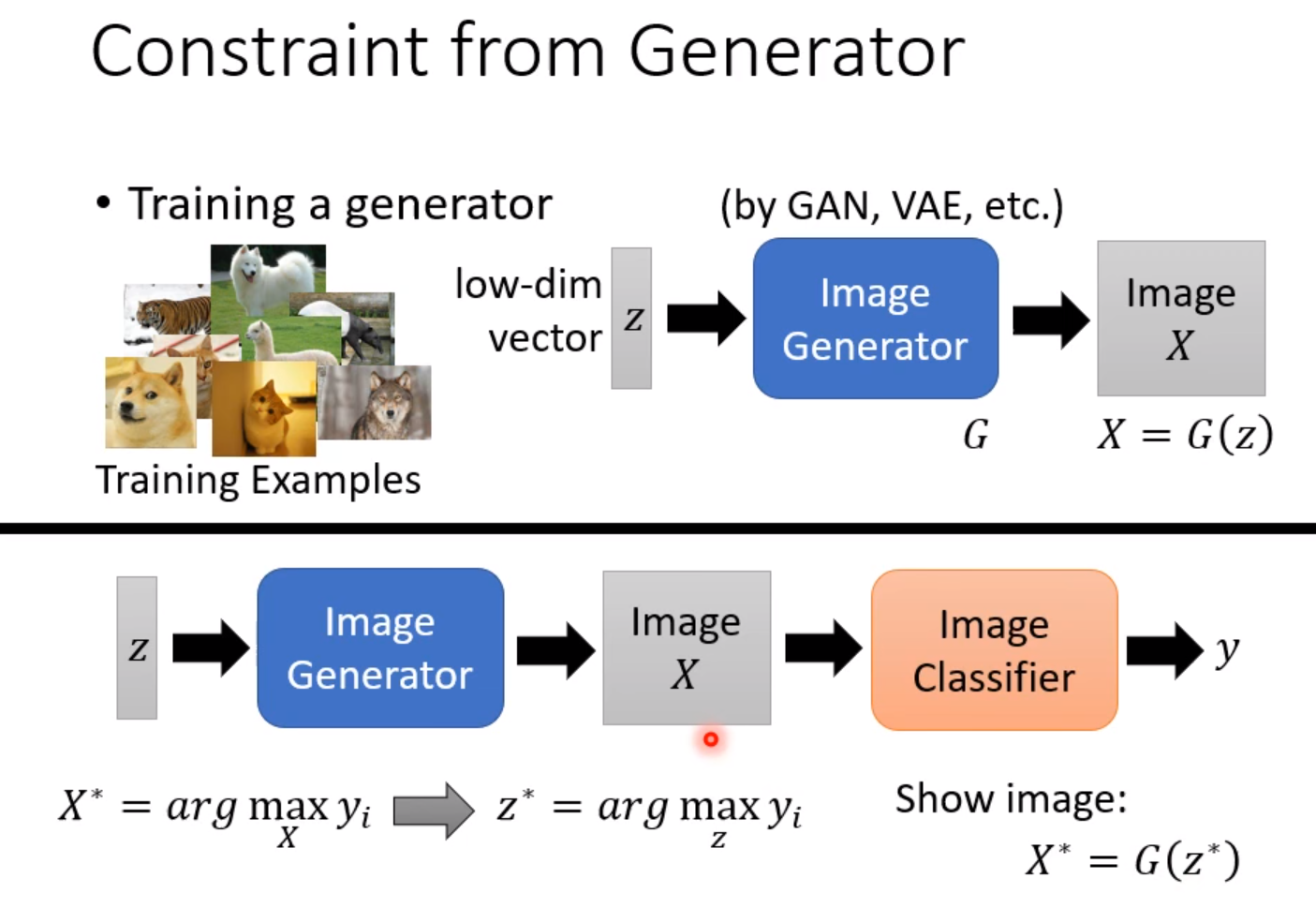
如果你想要看到非常清晰的图片,你可以训练Generator。这时候你的任务是找一个z使得这个z产生的图片丢到分类器中的信心分数越大越好。这样你就能得到一张非常标准的图片。