决策树图例:
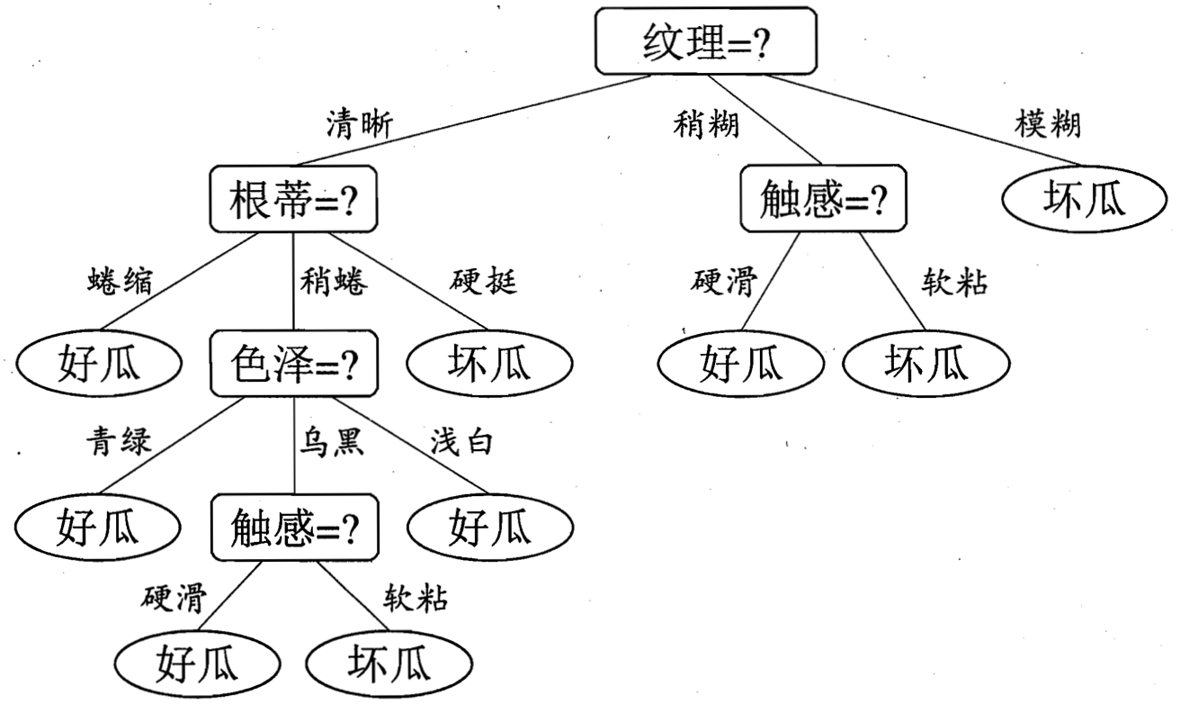
如果有这样一个图,我们在对数据进行离散化处理后,我们就能很容易地进行分类,那么这样一个图是怎么建立起来的呢?其中的每一个节点都是怎么确定的呢?
决策树学习的关键其实就是选择最优划分属性,希望划分后,分支结点的“纯度”越来越高。也就是说,每分一次,都使得数据越来越纯净,只包含更少类型的数据 ,或者其中的数据都明显具有更加相似的特征。
ID3算法
信息量
信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量x的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大。
那么信息量可以用以下公式表示($p(x_i)$为事情发生的概率):
$$
l(x_i) = -log_2p(x_i)
$$
而所有类别的信息期望值为:
$$
H = -\sum_{i=1}^{n}p(x_i)log_2p(x_i)
$$
因此当一个集合中混杂的数据类型越多,这个值就越大,当数据中只有一种类型时,这个值为0,也就完成了分类。因此,我们只要找到一个节点分类后的信息量最小,那么选择这个节点作为分类方法就是最好的选择。
信息增益
信息增益其实指的是信息量减少的量,把分支前的信息熵减去分支后信息熵的加权平均:
$$
G = H - \sum_{i=1}^{n}\frac{D_i}{D}H_i
$$
其中D是数据总量,$D_i$是一个分支中的数据量。因此信息增益越大,分类效果越好。



